
品味Deepseek-R1这份2025春节大餐,蒸馏技术不止高端白酒有,AI也有!
2025年1月20日,Deepseek发布R1版本,性能对标OpenAI o1正式版。
今天,我们正式发布 DeepSeek-R1,并同步开源模型权重。
-
DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。
-
DeepSeek-R1 上线 API,对用户开放思维链输出,通过设置model='deepseek-reasoner'即可调用。
-
DeepSeek 官网与 App 即日起同步更新上线。
性能对齐 OpenAI-o1 正式版
DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。
这是deepseek官网发布的内容,字少事大,经过一周的使用和对比。
在1月27日,deepseek迎来了出圈时刻。
在上周,来自中国DeepSeek的AI工程师团队所开创的DeepSeek R1大模型可谓霸榜美国热搜,并且DeepSeek应用已登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,在美区下载榜上超越ChatGPT,堪称属于中国AI的“里程碑时刻”。
为什么DeepSeek能够迅速出圈呢,除了性能超越最先进的大模型OpenAI-o1正式版,最重要的事训练成本大幅度降低,只需原来算力的2%。其关键技术就是后训练蒸馏技术,这个后面再展开讲。算力成本的降低,对靠堆算力来提高自己大模型能力的技术路线形成冲击。
DeepSeek团队证明,他们能够在没有世界最顶级的$英伟达 (NVDA.US)$高性能AI GPU提供强大AI算力的情况下,以极低成本加上性能普通的AI加速器训练出推理能力一流的突破式开源AI大模型,这也意味着未来大模型训练/推理比拼的不再是动辄千万亿美元的AI GPU算力战,极有可能是人人都能参与的“头脑风暴”。
DeepSeek R1的问世,宣告AI训练与推理成本大幅缩减,在不到600万美元的极低投入成本和2048块性能远低于H100与Blackwell的H800芯片条件下,DeepSeek团队打造出性能堪比OpenAI o1的开源AI模型,相比之下Anthropic与OpenAI训练成本高达10亿美元。该模型每百万个token的查询成本仅为0.14美元,而OpenAI的成本为7.50美元,成本降幅高达惊人的98%。
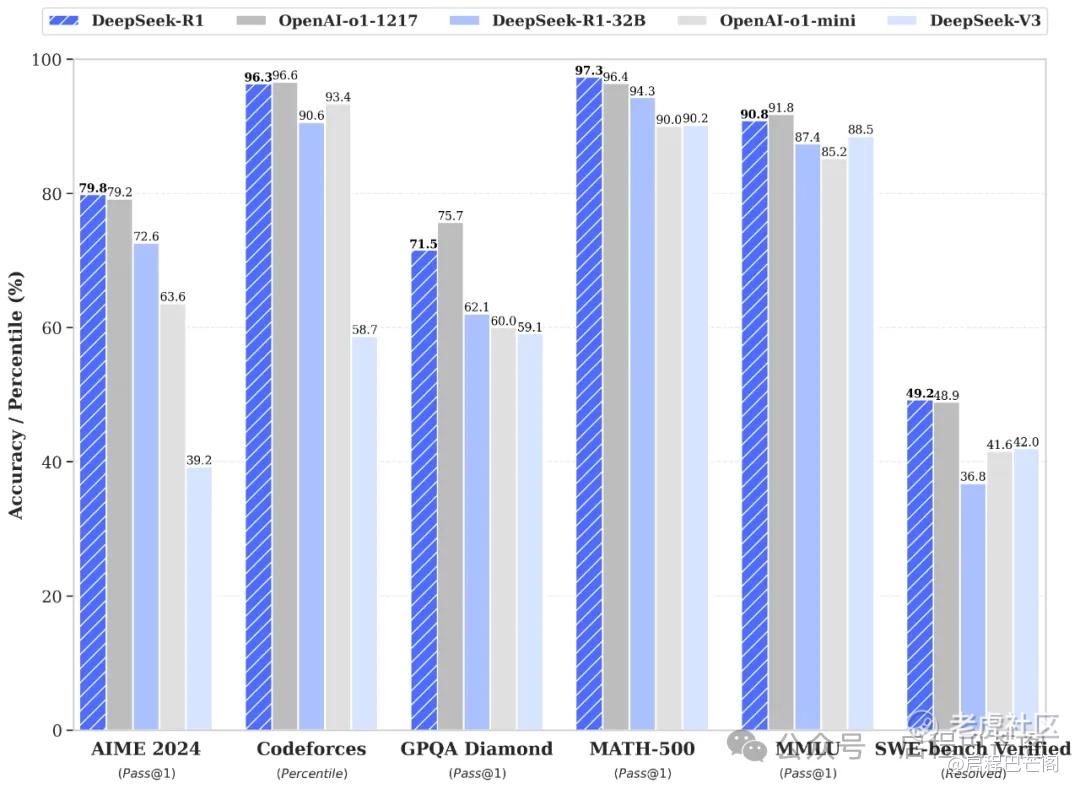
虽然训练/推理成本相比于GPT家族以及LIama开源大模型骤降,但是DeepSeek大模型的多个性能指标却位于行业顶尖水平。性能评估结果显示,通过纯强化学习方法训练得到的 DeepSeek-R1-Zero以及在此基础上改进的 DeepSeek-R1,在 2024 年AIME(美国数学邀请赛)测试中分别取得了 71.0% 和 79.8% 的成绩,与 OpenAI o1 的79.2%水平可谓并驾齐驱。DeepSeek-R1在算法类代码场景(Codeforces)以及GPQA、MMLU中的最终得分略低于OpenAI o1,但是在评估AI大模型在解决实际软件工程问题能力的SWE-Bench Verified方面,意外强于o1。
据了解,UC伯克利、港科大、HuggingFace等顶级学术团队与AI科技大拿们在上周纷纷成功复现DeepSeek,只用强化学习,没有监督微调,30美元就能见证所谓的“啊哈时刻”,即Aha moment,也被称作所训练的AI大模型的“顿悟时刻”。全球AI大模型,或许正在进入下一分水岭。
简而言之,DeepSeek通过“极致工程化、并行优化以及精筛数据”为核心来不断削减通用算力的“无效消耗”,把资源集中到最能提升模型性能的核心模块(注意力头、关键算子、RL/蒸馏微调等),展示了“极致工程化 + 后训练端蒸馏 + 专业数据整合+主攻强化训练”新范式如何在有限GPU 资源下逼近乃至超越行业主流大模型性能,对传统“巨额烧钱”模式提出了强力挑战。因此DeepSeek将硬件和算法的潜能最大化挖掘——这与过去很长一段时间美国科技大厂们“粗放式烧钱”在某种程度上形成鲜明对比。
何为后训练端蒸馏?
深度求索(DeepSeek)的后训练蒸馏(Post-Training Distillation)是一种模型压缩技术,旨在将大型预训练模型(教师模型)的知识迁移到更小、更高效的模型(学生模型)中,同时尽量保留原模型的性能。
1. 核心思想
-
知识迁移:通过模仿教师模型的输出(如概率分布、中间特征等),让学生模型学会“举一反三”,而非仅依赖原始训练数据的标签。
-
轻量化:学生模型参数量更小、推理速度更快,适合部署在资源受限的场景(如移动端、边缘设备)。
2. 关键步骤
-
教师模型选择:通常使用DeepSeek自研的大规模预训练模型(如数十亿参数的LLM)作为知识来源。
-
学生模型设计:设计更紧凑的模型结构(如减少层数、隐藏维度),或直接使用现有小模型(如TinyBERT、DistilBERT)。
-
蒸馏目标:
软标签蒸馏:最小化学生与教师模型输出的KL散度(捕捉概率分布中的暗知识)。
中间层对齐:对齐学生与教师模型的中间特征(如注意力权重、隐藏状态)。
任务损失:结合下游任务(如分类、生成)的原始损失函数,保持任务性能。
-
动态训练策略:
温度参数:调整softmax温度,控制输出分布的平滑度。
渐进蒸馏:分阶段迁移不同层次的知识(如先学输出层,再学中间层)。
3. 优势
-
高效部署:学生模型推理速度提升数倍,内存占用大幅降低。
-
性能保留:在多项NLP任务中,学生模型性能可达到教师模型的90%以上。
-
灵活性:可针对不同硬件(如GPU、手机芯片)定制学生模型结构。
受此影响,股票市场也迅速作出反应。
近几个月一直在争夺“全球股王”宝座的 $苹果 (AAPL.US)$ 和 $英伟达 (NVDA.US)$ ,在周一走上了截然不同的两条道路。
苹果公司周一收涨超3%,市值达到3.47万亿美元。而英伟达则大跌近17%,市值蒸发超5900亿美元后,只剩下2.9万亿美元。截至发稿,苹果再涨近2%,坐稳全球第一宝座。
小米也意外获益,在1月28日半个交易日,也上涨3.23%,一举突破38港币,当前市值9615亿港币,万亿港币市值近在咫尺。
不用多说,英伟达大跌的原因,是中国AI公司DeepSeek的技术突破引发部分投资者对长期算力需求的担忧。
惨痛大跌之际,英伟达周一回应媒体采访时表示,DeepSeek的(R1)新模型是一个“优秀的人工智能进步”,同时强调运行AI模型依然需要“大量的高性能英伟达GPU和高性能网络”。
为什么苹果意外收益于DeepSeek的技术突破呢?
如果DeepSeek的技术能够真正降低AI推理的成本,那么 $苹果 (AAPL.US)$ 将凭借其在边缘AI技术上的优势长期受益。
1月29日凌晨1点半,阿里云通义千问旗舰版模型Qwen2.5-Max正式升级发布。据其介绍,Qwen2.5-Max模型是阿里云通义团队对MoE模型的最新探索成果,预训练数据超过20万亿tokens,展现出极强劲的综合性能,在多项公开主流模型评测基准上录得高分,全面超越了目前全球领先的开源MoE模型以及最大的开源稠密模型。
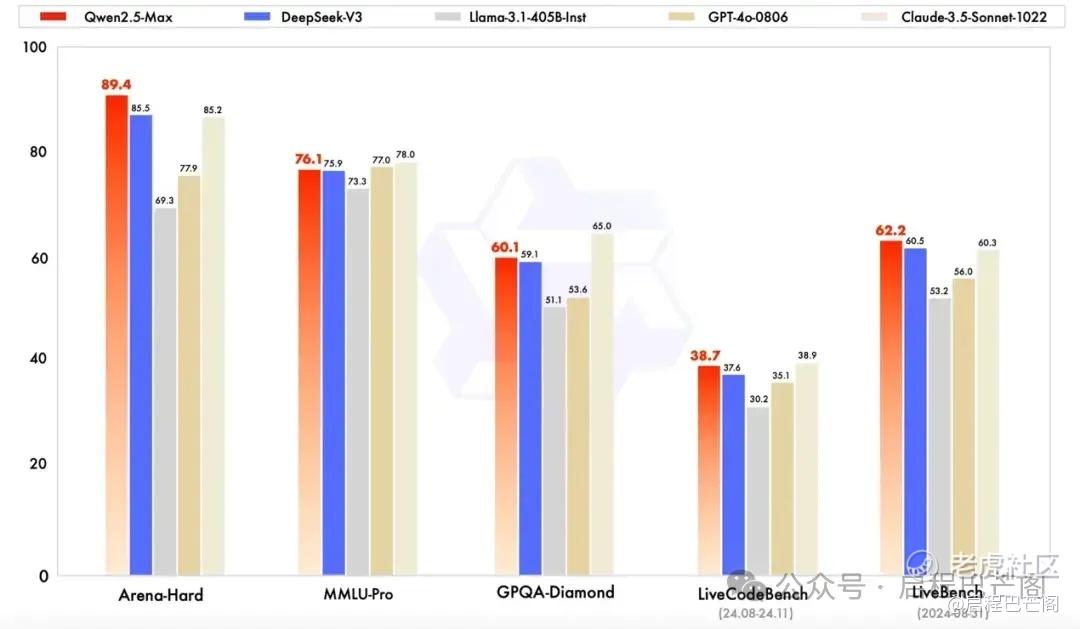
与Qwen2.5-Max进行对比的模型,就包括了最近火爆海内外的DeepSeek旗下的V3模型。受新模型的影响,$阿里巴巴 (BABA.US)$美股拉升,一度涨超7%,收盘录得6.71%的涨幅,报96.03美元/股。
1月29日,美国人工智能公司OpenAI声称,发现了证据证明DeepSeek使用OpenAI的专有模型来训练自己的模型。
OpenAI告诉媒体,公司已经发现了一些“蒸馏”的证据。“蒸馏”指的是将较大、功能较强的模型的知识,提炼到较小的模型中,这个较小的模型性能较好且成本较低。
回顾事件起因,上周,中国量化巨头幻方量化旗下大模型公司DeepSeek推出了新模型DeepSeek-R1,该模型在数学、编程和推理等关键领域的表现能媲美OpenAI的最强推理模型o1。
蒸馏在行业中很常见,但OpenAI的服务条款不允许这种做法,规定用户不能复制其服务和“输出开发与OpenAI竞争的模型”。OpenAI未进一步置评,也没有提供证据的细节。
幻方量化什么来头,梁文峰有何许人也,再挖一挖。
幻方量化这听起来像是一个做量化交易的公司,没错,就是一个幻方量化就是一个做量化交易的私募公司。
梁文锋正是头部量化私募幻方量化创始人、DeepSeek的创始人。
作为一名“80后”,梁文锋本科、研究生都就读于浙江大学,拥有信息与电子工程学系本科和硕士学位。
2008年起,梁文锋就开始带领团队使用机器学习等技术探索全自动量化交易。2015年,幻方量化正式成立,2019年,其资金管理规模就突破百亿元。
2019年,梁文锋在当年的金牛奖颁奖仪式上,发表主题演讲《一名程序员眼里中国量化投资的未来》,这是他罕有的公开发言。
在演讲中,梁文锋指出,量化与非量化的判定标准就是在投资决策的过程中,是用数量化方法进行决策的,还是用人进行决策的。量化公司是没有基金经理的,基金经理就一堆服务器。
“作为私募,投资人对我们的期望是很高的,如果一年跑赢指数低于25%,投资人是不满意的。”梁文锋指出,量化投资已经赚了技术面流派原来赚的钱,未来也要抢夺基本面流派原来赚的钱。
演讲最后,梁文锋说,幻方量化的使命就是提高中国二级市场的有效性。
2021年,幻方量化成为国内首家突破千亿规模的的量化私募大厂,被称为国内量化私募“四大天王”之一。
一个做量化的,怎么搞起大模型,印象中只有互联网大厂在搞,像百度的文新一言,腾讯的混元,阿里巴巴的通义千问。
梁文锋对于AI的兴趣早就有迹可循。
2016年10月21日,幻方量化推出第一个AI模型,第一份由深度学习生成的交易仓位上线执行,使用GPU进行计算。2017年,幻方量化宣称实现投资策略全面AI化。
幻方量化官网显示,其在2018年就确立以AI为公司的主要发展方向。
2020年开始,幻方累计投资超亿元、占地面积相当于一个篮球场的AI超级计算机“萤火一号”正式投入运作,号称可以匹敌4万台个人电脑的超级算力。2021年,幻方投入十亿建设“萤火二号”,以“任务级分时共享”为核心理念,调度系统秒级响应,平台配备强大的软件层支持:高性能算子库(hfai.nn)、分布式训练通讯框架(hfreduce)、专为AI开发而生的大容量高带宽文件系统(3FS),让AI模型能自如拓展到多节点之上,进行大规模并行训练,算力扩容翻倍,集群连续满载运行,平均占用率达到96%以上。
2021年,在梁文锋参与的论文中提到,他们正在部署的萤火二号系统,“配备了1万张A100GPU芯片”,在性能上接近DGX-A100(英伟达推出的人工智能专用超级计算机),但成本降低了一半,同时能耗减少了40%。
当时国内超过1万枚GPU的企业不超过5家,而且除了幻方量化之外,其他4家公司都是互联网大厂。
这背后需要极其雄厚的财力支持。
DeesSeek的简单发展史
2023年7月,幻方量化宣布成立大模型公司DeepSeek,正式进军通用人工智能领域。据报道,DeepSeek包括创始人梁文锋在内,仅有139名工程师和研究人员。与之对比,OpenAI有1200名研究人员,Anthropic则有500多名研究人员。
仅仅不到一年的2024年5月,DeepSeek就发布了DeepSeekV2,因为创新的模型架构和史无前例的性价比,火爆出圈。DeepSeek-V2的API定价为每百万tokens输入1元、输出2元,价格仅为GPT-4 Turbo的百分之一。
对于为何能做到如此高的性价比,DeepSeek官方解释称,DeepSeek-V2采用了创新的架构,例如注意力机制方面的MLA(多头潜在注意力)和前馈网络方面的DeepSeekMoE架构等,以实现具有更高经济性的训练效果和更高效的推理。
因此, DeepSeek被称为“AI界的拼多多”,引发了字节、阿里、百度等大厂的大模型价格战,纷纷宣布大模型产品降价。彼时,梁文锋在接受媒体采访时称,DeepSeek无意成为行业鲇鱼,低价背后是希望算力普惠。
2024年12月27日,DeepSeek-V3更是横空出世,火爆全球。据DeepSeek官网显示,其评测成绩不仅超越了Qwen2.5-72B(阿里自研大模型)和Llama 3.1-405B(Meta自研大模型)等顶级开源模型,甚至能和GPT-4o、Claude 3.5-Sonnet(Anthropic自研大模型)等顶级闭源模型一较高下。
DeepSeek宣布上线并同步开源DeepSeek-V3模型之外,还公布了长达53页的训练和技术细节。得到大幅升级的V3模型是在一个“难以想象”的预算下训练完成的:整个训练仅花费了557.6万美元,在2048块英伟达H800 GPU(针对中国市场的低配版 GPU)集群上运行55天完成,仅是OpenAI GPT-4o模型训练成本的不到十分之一。
就在1月20日, DeepSeek正式发布DeepSeek-R1模型。该模型在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。DeepSeek称,R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。DeepSeek不仅将R1训练技术全部公开,还蒸馏了6个小模型开源给社区,允许用户借此训练其他模型。
我说DeepSeek怎么对估值的理解如此之深呢,原来起源于量化,难怪。
以下是我跟DeepSeek的一段对话“用老唐估值法 给茅台估值,站在2024视角”


免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
- 究极键盘手·01-30这简直是AI领域的革命啊!感谢分享这个传奇故事 [强]点赞举报
- 你还会爱吗·01-30太厉害了!👍点赞举报
